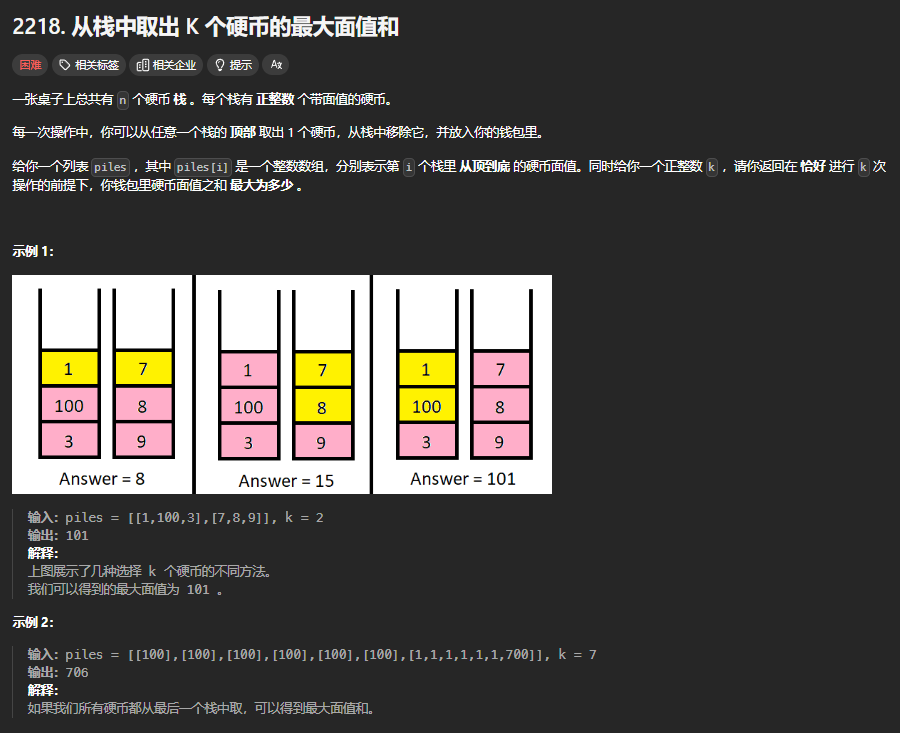
LeetCode 2218
如何遍历所有情况并比较大小
解题思路
1. 问题分析
这是一个典型的动态规划问题,我们需要:
- 从n个硬币栈中,每次只能从栈顶取硬币
- 总共取k次
- 求取得的硬币面值和的最大值
关键点:
- 每个栈都是从顶到底排列的
- 每次只能取栈顶的硬币
- 必须恰好取k个硬币
2. 动态规划设计
状态定义
dp[i][j] 表示:从前i个栈中取j个硬币能获得的最大面值和
状态转移
对于第i个栈,我们可以:
- 不从这个栈取硬币:dp[i][j] = dp[i-1][j]
- 从这个栈取x个硬币:dp[i][j] = dp[i-1][j-x] + (第i个栈顶部x个硬币的和)
最终的状态转移方程:
dp[i][j] = max(dp[i-1][j], dp[i-1][j-x] + sum(piles[i]前x个))
其中x的范围是:1 ≤ x ≤ min(栈i的大小, j)
初始化
- dp[0][0] = 0
- 其他初始值设为负无穷,表示无法达到
结果
最终答案就是dp[n][k],表示从n个栈中取k个硬币的最大面值和
3. 时间复杂度分析
- 设n为栈的数量,k为需要取的硬币数,m为每个栈的平均大小
- 状态数:O(n*k)
- 每个状态的转移需要O(m)次运算
- 总时间复杂度:O(nkm)
4. 空间复杂度分析
需要一个二维dp数组,空间复杂度为O(n*k)
5. 优化思路
- 可以使用滚动数组优化空间复杂度到O(k)
- 对于每个栈的前缀和可以预处理,避免重复计算
- 如果 k 较小,可以考虑使用记忆化搜索的方式
代码实现(Python)
1 | from typing import List |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Never Settle!
评论
